What's InnoQos
映像配信専門の
システムインテグレーター
会社は12年目、実績も多数。
実は、メディア系のお客様の事業を支えている”クロコ”の会社
コロナ過を経て、新しい働き方も模索中。
Scroll
Why InnoQos InnoQosが選ばれ続ける理由



Service サービスのご紹介
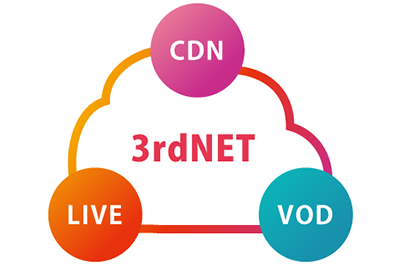
イノコスが提供する月額サービス

Solution
ソリューションの
ご紹介
海外ベンダの主要メディアソリューション
Products
メーカー別
お取扱い製品


Case Study メディア関連のお客様を中心に50社以上のお取引がございます



























ロゴの掲載はご承諾を頂いたお客様のみ掲載しております。






News 新着情報
- 製品サポート2024.03.08Videon社「LiveEdge® Node」を使用したグラフィックオーバーレイに関するコラムを掲載しました
- お知らせ2023.12.22製品情報にVideonを追加 (2024.3.8 更新)
- 展示会情報2023.11.08Inter BEE 2023 出展のお知らせ 11月15日~17日
- 展示会情報2023.07.19ケーブル技術ショー2023に出展 デジタルサイネージの【KAWARA板ネット】を展示致します。画や動画だけではなくLive配信の表示も可能なので、CATV局様が制作したコンテンツの利用シーンを増やすことができます。合わせて、放送伝送用ソリューションのHarmonic社製ProStream-Xも展示致します。HOG受信の具体的な構成もご案内します。
- 製品サポート2023.05.31映像配信サービス_イノコス3rdNET月額使用料一部改定のお知らせ
Contact お問い合わせ
弊社の製品・ソリューションに関するご質問やご相談、資料請求のご依頼など、お問い合わせフォームをご利用ください。